
SQL은 선언적인 언어로 매우 쉽다. 외국에서는 "SEQUEL"이라고 한다. 앞에서 배웠던 tabe, row, column으로 이루어져 있다.
SQL schema
CREATE SCHEMA COMPANY(이름) AUTHORIZATION 'Ushin';
Schema name과 각 element에 대한 권한, 설명을 함께 표기한다.
Catalog
Schema는 여러개일 수 있다. Schema들의 이름을 모아둔 것을 catalog라고 한다.
CREATE TABLE
CREATE TABLE COMPANY.EMPLOYEE
or
CREATE TABLE EMPLOYEE
Table도 만들 수 있다. 이런 table들을 필요에 맞게 view의 형태로 보여줄 수 있다. 실제로 table을 만들어서 물리적으로 저장하는 것이 아니라 임시로 만들어진다. CREATE VIEW로 가능하다.

Foreign Key 설정은 약간의 error를 발생시킬 가능성이 있다. 가령, 상호 참조를 하거나 아직 만들어지지 않은 table을 참조하는 에러가 발생할 수 있다. 보통은 table을 다 만들고 foreign key 등의 설정을 진행하여 의도하지 않은 error를 피한다.
Attribute Data Types
| Numeric | Char(string) | Bit-string | Boolean | DATE |
| INT FLOAT DOUBLE |
CHAR(n) VARCHAR(n) : n byte 잡아두고 사용하는 만큼만 저장한다. |
BIT(n) BIT VARYING(n) BLOB(n) |
TRUE FALSE NULL |
YEAR MONTH DAY |
여러가지 명령어들
| Schema | CREATE SCHEMA COMPANY(이름) AUTHORIZATION 'Ushin'; |
| Table | CREATE TABLE COMPANY.EMPLOYEE ~; or CREATE TABLE EMPLOYEE ~; |
| Domain | CREATE DOMAIN SSN_TYPE AS CHAR(9); |
| Type | CREATE TYPE ~; |
| Check | (Attribute) (type) CHECK (condition); |
| Primary key | (Attribute) (type) PRIMARY KEY; |
| Unique | (Attribute) (type) UNIQUE; |
Constraints in SQL
앞에서 봤던 제약들이다.
| Key constraint | Key value는 중복이 되면 안된다. |
| Entity Integrity constraint | Primary key는 null이 되면 안된다. |
| Referential Integrity constraint | Foregin key는 값이 있는 Primary key(혹은 null)를 참조한다. |
| Domain constraint | 허용된 attribute 범위에 있는 값이어야 한다. |
| Null constraint | Null 허용여부에 따라 사용이 가능하다. |
Foregin key violation
SET NULL, CASCADE, SET DEFAULT의 대응이 가능하다.
| SET NULL | CASCADE | SET DEFAULT |
| FK = null | 지워지는 PK 값을 FK에 넣기 | Default 값으로 설정 |
Giving name to Constraints
Constraint에 이름을 줄 수 있다.

CHECK를 이용해서 constraint을 줄 수도 있다.
CHECK (Dept_create_date <= Mgr_start_date)
Basic Retrieval Queries in SQL
SELECT 명령어를 이용하면, 2개 이상의 tuple들이 결과로 나오는데, 이 때 중복되는 값이 있을 수 있다. Relational model에서는 중복을 허용하지 않았던 것과 상반된다. 중복되는 tuple을 Multiset or Bag behavior라고 한다.
Attribute 간에 PK나 unique한 값이 아니라면, 중복되는 값은 있을 수 밖에 없기 때문에 발생하는 일이다. DISTINCT 명령어나 집합 명령어를 통해 중복을 지워줄 수도 있다.
SELECT statement
SELECT <attribute list>
FROM <table list>
WHERE <condition>
GROUP BY <grouping attribute>
HAVIING <grouping condition>
ORDER BY <attribute list>
예시는 다음과 같다.

기억해야할 점은, WHERE이 없으면 모든 가능한 조합이 결과로 나온다. 애매한 경우 table의 이름을 명시할 수도 있으며, aliasing도 가능하다.

특정 attribute를 고르지 못하는 경우에는 *를 이용해 모든 attribute를 선택하여 결과를 볼 수 있다.
Set operation
UNION(합집합), EXCEPT(차집합), INTERSECT(교집합)의 명령어가 있다. 중복을 허용하는 것을 원하면 UNION ALL처럼 명시해줘야 한다. 기본적으로 DISTINCT이다.

Pattern Matching
LIKE와 BETWEEN이 있다.
WHERE ssn LIKE '__1__3456'
WHERE ssn LIKE '%34%'
WHERE (ssn BETWEEN 3013 AND 4031) AND dno=5;
Arithmetic operation
SELECT 사용시에 사칙연산을 이용해 검색할 수 있다.

Ordering of query results
ORDER BY D.Dname DESC, E.Lname ASC, E.Fname ASC
ORDER BY <attribute list>에 의해 나오는 결과는 기본적으로 ascending(오름차순)이다. Descending을 원하면 DESC라고 명시해줘야 한다.
INSERT
CREATE TABLE에서 만들어둔 attribute 순서를 지켜서 입력해줘야 한다.
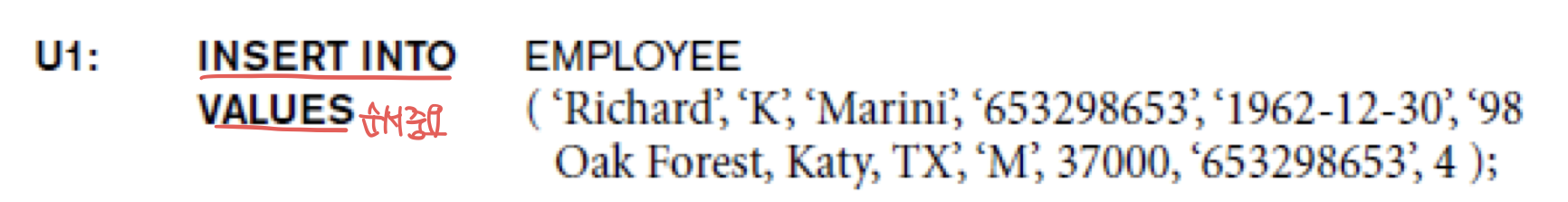


DELETE

WHERE 조건을 적어주지 않으면, 모든 data를 삭제하게 된다. 비슷한 명령어로 DROP이 있다. DELETE는 저장된 정보만을 지우는 반면, DROP은 해당 table 자체를 지우는 방법이다.
UPDATE

SET과 함께 사용된다. SET은 변경할 attribute와 변결될 값을 명시해야 한다.

WHERE-WHERE도 가능하다.